Continuous Delivery avec Argo CD
Bonjour à tous, dans cet article nous allons parler de continuous delivery, de livraison continue quoi.
Disclaimer : On va parler d'Argo CD, mais aussi de Prometheus, Helm, Grafana, HPA etc.
Avec la montée en puissance de la mouvance DevOps et de l'industrialisation des processus d'entreprise, certaines sociétés et grands groupes n'ont pas hésité à développer des solutions d'automatisation comme Amazon, Google ou encore JetBrains.
La communauté open source n'a pas hésité à développer et partager ces propres outils. Nous pensons à Gitlab CD/CD, CircleCI, Travis CI ou encore Jenkins.
Utilisateur quotidien de Jenkins ou encore Gitlab CI/CD pour mes différentes taches de tests unitaires, de performance ou encore de sécurité, plus orienté intégration continue donc, je me suis davantage intéressé à la livraison continue. Développeur de cœur, j'utilise tous les jours Gitlab pour son principal service de versioning, mais aussi de Continuous Integration.
Je cherchais donc un outils GitOps.
C'est la semaine dernière en traînant sur le site de la Cloud Native Computing Foundation (CNCF pour les intimes) que je suis tombé sur leur carte interactive référençant un grand nombre de projets, chacun dans leur catégorie de la chaîne DevOps. En regardant de plus près la catégorie Continuous Integration & Delivery, je suis tombé sur le projet Argo, qui est un projet au stage de l'incubation (incubating) au sein de la CNCF.
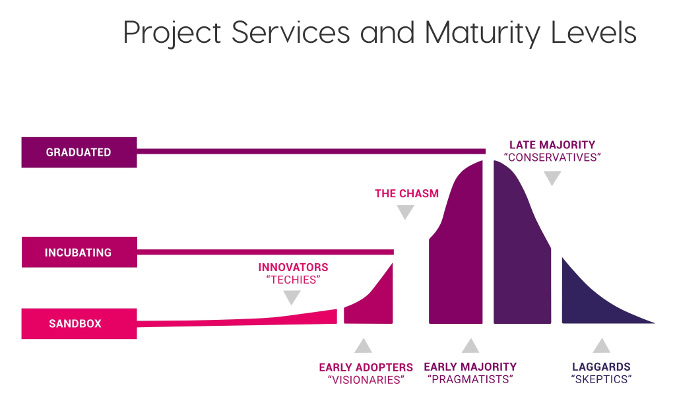
Pour rappel, Kubernetes, Prometheus, Helm, ou encore Harbor sont des projets open source au stade graduated, ou certifié et validé par la CNCF.
Argo, une communauté au service de Kubernetes
Pour la faire rapide, Argoproj est un ensemble d'outils et de projets permettant de travailler avec Kubernetes.
Les principaux projets type Continuous Delivery que nous pouvons retrouver sur leur Github et qui vont nous intéresser sont les suivants :
-
Argo Rollout : grâce à l'utilisation de la ressource personnalisée Rollout, Argo fournit des stratégies de déploiement telles que le modèle Blue Green et Canary
-
Argo CD : un outil GitOps / CD pour Kubernetes.
Pour le reste, je vous recommande d'aller voir leurs repos très intéressant sur Github.
Vous l'aurez compris, le projet dont nous allons parler est Argo CD.
Prérequis pour le lab
Dans cet atelier, nous allons mettre en place une chaîne automatique de livraison continue. Nous passerons rapidement sur le côté intégration, tests unitaires, E2E, de sécurité ou autre. Nous allons axer ce lab sur la partie CD.
Pour ce faire, vous allez avoir besoin des prérequis suivants :
- un cluster Kubernetes (je sais…)
- Helm v3
L'objectif est de mettre en place :
- une stack avec un site web statique basé sur nginx
- une stack de monitoring de vos pods avec prometheus-operator et prometheus-adapter
- une façon de récupérer les métriques des pods avec metrics-server
- un autoscaler horizontal de pods (HPA)
- Argo CD (évidemment)
Pour ma part, mon cluster est composé d'un nœud master et de 3 workers.
Versions de kubectl client / serveur et d'Helm
Versions de kubectl client / serveur :
1root@lab-kubernetes-1:~# kubectl version
2Client Version: version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.5", GitCommit:"e6503f8d8f769ace2f338794c914a96fc335df0f", GitTreeState:"clean", BuildDate:"2020-06-26T03:47:41Z", GoVersion:"go1.13.9", Compiler:"gc", Platform:"linux/amd64"}
3Server Version: version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.3", GitCommit:"2e7996e3e2712684bc73f0dec0200d64eec7fe40", GitTreeState:"clean", BuildDate:"2020-05-20T12:43:34Z", GoVersion:"go1.13.9", Compiler:"gc", Platform:"linux/amd64"}
Version d'Helm :
1root@lab-kubernetes-1:~# helm version
2version.BuildInfo{Version:"v3.2.3", GitCommit:"8f832046e258e2cb800894579b1b3b50c2d83492", GitTreeState:"clean", GoVersion:"go1.13.12"}
Installation des outils de monitoring
Metrics Server
Metrics Server est un service efficace de métrologie des ressources en conteneurs dans K8S.
Pourquoi utiliser Metrics Server ?
Comme rappelé dans la documentation officielle, vous aurez besoin de déployer Metrics Server si :
- Vous avez besoin d'un système de scalabilité horizontal basé sur la CPU / Mémoire (HPA), ce qui est notre cas,
- Ajuster / suggérer automatiquement les ressources nécessaires aux conteneurs (VPA), ce qui n'est pas notre cas.
Vous n'avez cependant pas besoin de Metrics Server si vous avez :
- Des environnements non Kubernetes,
- Besoin d'une source performante et précise de mesures de l'utilisation des ressources,
- Un système HPA basé sur des ressources autres que la CPU / Mémoire.
Pour installer Metrics Server, rien de plus simple :
1root@lab-kubernetes-1:~# kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.3.6/components.yaml
2clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
3clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
4rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
5apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
6serviceaccount/metrics-server created
7deployment.apps/metrics-server configured
8service/metrics-server created
9clusterrole.rbac.authorization.k8s.io/system:metrics-server created
10clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
Vérification de Metrics Server :
1root@lab-kubernetes-1:~# kubectl get pods -n kube-system -l k8s-app=metrics-server
2NAME READY STATUS RESTARTS AGE
3metrics-server-5f956b6d5f-dp9vp 1/1 Running 0 52s
Pour vérifier que tout fonctionne correctement, nous pouvons faire un top sur nos nœuds par exemple :
1root@lab-kubernetes-1:~# kubectl top node
2error: metrics not available yet
Si comme moi vous rencontrez cette erreur, c'est parce que par défaut, Metrics Server communique au travers d'un canal sécurisé, avec le certificat auto-signé de votre cluster Kubernetes.
Pour outrepasser cette contrainte, nous pouvons éditer le déploiement de Metrics Server de la façon suivante :
1root@lab-kubernetes-1:~# kubectl edit deployment metrics-server -n kube-system
Modifier les arguments du container metrics-server :
1...
2 spec:
3 containers:
4 - args:
5 - --cert-dir=/tmp
6 - --secure-port=4443
7 - --kubelet-insecure-tls
8...
Attention, comme le rappelle la documentation officielle, cet argument permet de : Do not verify the CA of serving certificates presented by Kubelets. For testing purposes only.
Enregistrer, et faire à nouveau un top node pour récupérer les métriques :
1root@lab-kubernetes-1:~# kubectl top node
2NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
3lab-kubernetes-1 305m 15% 2838Mi 35%
4lab-kubernetes-2 348m 8% 5490Mi 46%
5lab-kubernetes-3 554m 13% 6250Mi 52%
6lab-kubernetes-4 427m 10% 6295Mi 52%
Prometheus Operator
Pourquoi Prometheus Operator ? Si vous avez déjà manipulé Prometheus, vous savez que c'est une plateforme de monitoring qui collecte les métriques des applications cibles sur les endpoints HTTP exposés des dites applications. Ce qu'il faut savoir c'est qu'à chaque fois que vous ajoutez / supprimez une application, il faut modifier le fichier de configuration de Prometheus.
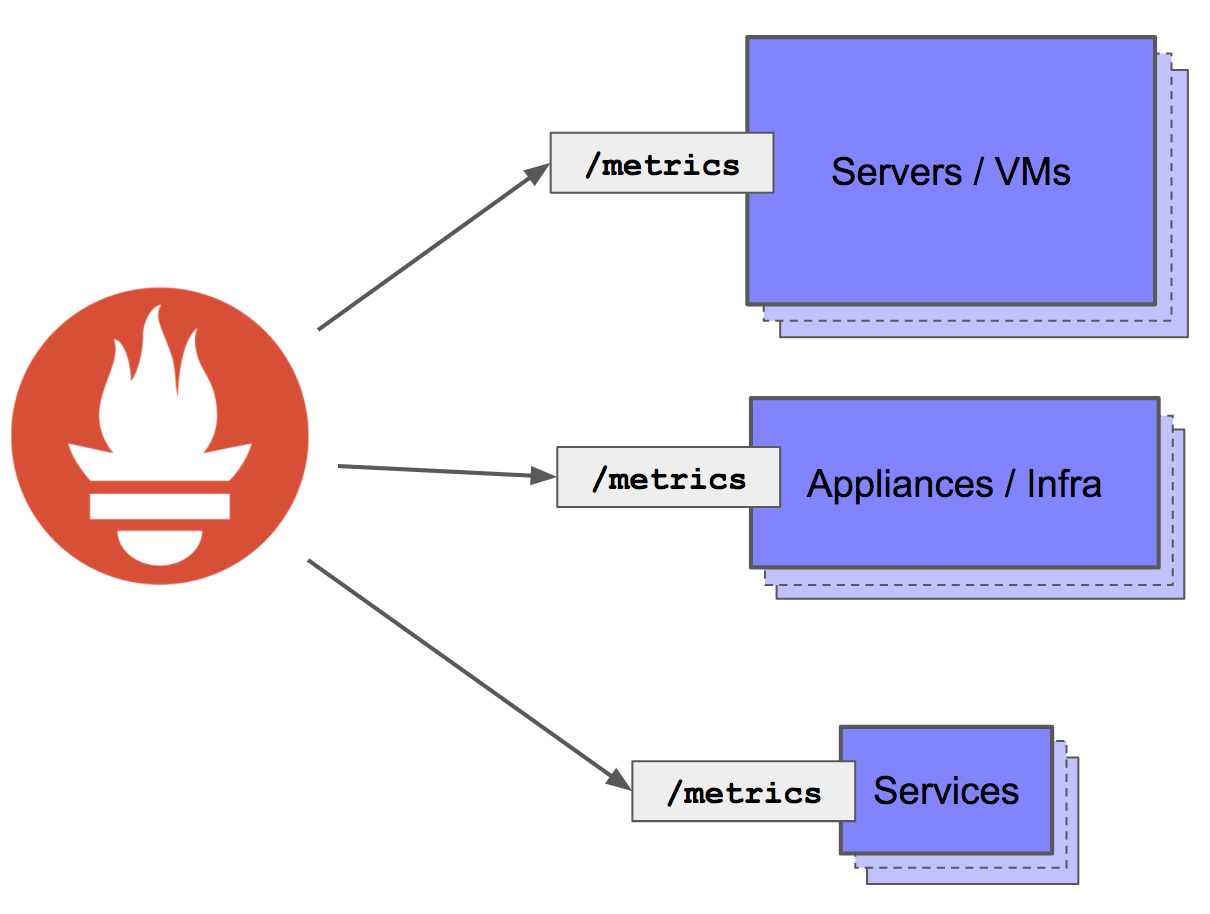
Afin d’accélérer et faciliter cette étape chronophage, nous allons utiliser Prometheus Operator.
Prometheus Operator permet à Kubernetes de gérer de façon native les déploiements, le management de Prometheus et de ses composants. L'objectif de ce projet est de simplifier et d'automatiser la configuration de Prometheus pour des clusters Kubernetes.
Ajout du repository Helm stable et mise à jour
1root@lab-kubernetes-1:~# helm repo add stable https://kubernetes-charts.storage.googleapis.com
2"stable" has been added to your repositories
3root@lab-kubernetes-1:~# helm repo update
4Hang tight while we grab the latest from your chart repositories…
5…Successfully got an update from the "stable" chart repository
6Update Complete. ⎈ Happy Helming!⎈
Installation de Prometheus Operator
Une bonne habitude (je crois) que j'ai prise est de toujours inspecter les valeurs de la chart Helm à installer. Par exemple si vous voulez tuner votre installation, il est toujours intéressant de connaître les valeurs par défaut et mises à disposition dans le Chart.
1root@lab-kubernetes-1:/opt/prometheus-grafana# helm inspect values stable/prometheus-operator > prometheus-operator.yaml
N'hésitez pas à regarder en détail ce fichier pour qu'il corresponde le plus à vos besoins, comme l'ajout d'ingress ou la modification du type des services. Pour notre lab, je ne modifierai pas ce fichier, et j'exposerai les différents services en CLI.
Si vous voulez davantage d'informations concernant l'architecture de Prometheus Operator ainsi que sur ses différents CRDs (Custom Resource Definition), vous trouverez ici un article très intéressant écrit par Germain Lefebvre et Antoine Leteneur via ce lien.
Maintenant que le fichier est adapté à nos besoins, nous pouvons déployer la stack. Pour ce faire, nous allons d'abord créer le namespace metrics dans lequel l'ensemble de nos services de monitoring seront déployés :
1root@lab-kubernetes-1:~# kubectl create namespace metrics
2namespace/metrics created
Déploiement de la stack :
1root@lab-kubernetes-1:/opt/prometheus-grafana# helm upgrade --install -f prometheus-operator.yaml prometheus-operator stable/prometheus-operator --namespace metrics
2manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
3manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
4manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
5manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
6manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
7manifest_sorter.go:192: info: skipping unknown hook: "crd-install"
8Release "prometheus-operator" has been upgraded. Happy Helming!
9NAME: prometheus-operator
10LAST DEPLOYED: Fri Jul 17 11:44:59 2020
11NAMESPACE: metrics
12STATUS: deployed
13REVISION: 1
14NOTES:
15The Prometheus Operator has been installed. Check its status by running:
16 kubectl --namespace metrics get pods -l "release=prometheus-operator"
17
18Visit https://github.com/coreos/prometheus-operator for instructions on how
19to create & configure Alertmanager and Prometheus instances using the Operator.
Vérification :
1root@lab-kubernetes-1:~# kubectl --namespace metrics get pods
2NAME READY STATUS RESTARTS AGE
3alertmanager-prometheus-operator-alertmanager-0 2/2 Running 0 97s
4prometheus-operator-grafana-75554df8c9-qg64r 2/2 Running 0 97s
5prometheus-operator-kube-state-metrics-69fcc8d48c-ddfrk 1/1 Running 0 97s
6prometheus-operator-operator-6bbc476477-82ddc 2/2 Running 0 97s
7prometheus-operator-prometheus-node-exporter-7hrgm 1/1 Running 0 97s
8prometheus-operator-prometheus-node-exporter-nfdmz 1/1 Running 0 97s
9prometheus-operator-prometheus-node-exporter-twcsc 1/1 Running 0 97s
10prometheus-operator-prometheus-node-exporter-vcrfh 1/1 Running 0 97s
11prometheus-prometheus-operator-prometheus-0 3/3 Running 1 97s
Nous constatons que le Chart a déployé un Node-exporter pour chacun de nos nœuds K8S, un Alertmanager, un Grafana et le serveur Prometheus.
Nous allons exposer Grafana ainsi que Prometheus afin d'y avoir accès au travers du navigateur web :
1root@lab-kubernetes-1:~# kubectl expose deployment prometheus-operator-grafana --type=NodePort --name=grafana-nodeport -n metrics
2service/grafana-nodeport exposed
1root@lab-kubernetes-1:~# kubectl expose service prometheus-operator-prometheus --type=NodePort --name=prometheus-service-nodeport -n metrics
2service/prometheus-service-nodeport exposed
1root@lab-kubernetes-1:~# kubectl get svc -n metrics
2NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
3....
4grafana-nodeport NodePort 10.110.121.212 <none> 80:32259/TCP,3000:32752/TCP 36s
5prometheus-service-nodeport NodePort 10.96.198.206 <none> 9090:31112/TCP 6s
6...
Nous pouvons maintenant accéder à Prometheus et Grafana à partir de l'IP d'un de nos nœuds Kubernetes, sur le port 32752 pour Grafana et sur le port 31112 pour Prometheus.
Les identifiants de connexion par défaut pour Grafana sont : admin / prom-operator.
Vous pourrez constater que Grafana vient avec une batterie de tableaux de bord déjà prêt à l’emploi, ce qui est appréciable.
Création de notre application web et création d'un Chart
Notre application web va être un simple site web statique basé sur Nginx. Afin de simplifier la continue avec Argo CD, nous allons choisir le déploiement basé sur Helm.
Pour la création de mon Chart, je me suis fortement basé sur celui de Bitnami. Effectivement, afin de monitorer notre application grâce à Prometheus Operator, il va falloir déployer un container side-car au sein de notre pod afin de scraper les métriques de notre container Nginx.
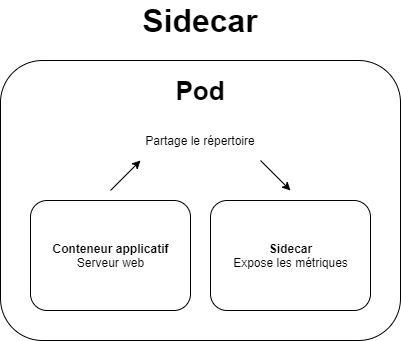
De cette façon, nous n'exposons pas nos métriques au monde entier, seulement à Prometheus.
Pour commencer, voici la commande pour créer le Chart :
1helm create helm-argocd-website
Il ne reste plus qu'à modifier les éléments dont nous avons besoin pour notre déploiement dans le dossier templates, soit :
- un HPA, pour la scalabilité horizontale de nos pods,
- un Service Monitor, pour que Prometheus Operator puisse modifier à la volée sa configuration en ajoutant le scraping de ce service monitor
Les modifications que j'ai apportées sont les suivantes :
- Ajout d'une entrée sous metrics.autoscaling dans le fichier values.yaml : targetRequestPerSecond: 50, qui va définir la valeur par défaut à partir de laquelle l'autoscaling va se mettre en place (si le nombre de requêtes par seconde dépasse 50)
- Ajout dans le fichier templates/hpa.yaml la métrique qui a pour nom my_nginx_http_requests_total, de type Pods, sur laquelle notre Prometheus va scraper
- Modification du fichier templates/deployment.yaml pour ajouter le pod side-car qui va requêter le endpoint 127.0.0.1:8080/status quand le Service Monitor va requêter sur /metrics
- Modification du fichier Nginx default.conf pour que seulement 127.0.0.1 soit autorisé à requêter l'endpoint /status
Et d'autres modifications dont je vous laisserai le soin de vous approprier et prendre connaissance sur mon GitLab ici, sinon l'article va être trop long et je vais finir par faire des podcasts.
Maintenant que votre Chart est ok et que votre fichier .gitlab-ci.yml l'est aussi, vous n'avez plus qu'à tout pousser sur votre Git. Nous allons maintenant (enfin) parler de Argo CD, le déployer et l'utiliser.
Déploiement d'Argo CD
Maintenant que votre environnement de monitoring est ok, nous allons déployer Argo CD. Pour ce faire, j'ai suivi la documentation officielle ici. Rien de compliquer, en 2 lignes c'est réglé pour du QuickStart. Je vous recommande tout de même de prendre connaissance du fichier install.yml et de le modifier si nécessaire :
1root@lab-kubernetes-1:~# kubectl create namespace argocd
2namespace/argocd created
3root@lab-kubernetes-1:~# kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
4customresourcedefinition.apiextensions.k8s.io/applications.argoproj.io created
5customresourcedefinition.apiextensions.k8s.io/appprojects.argoproj.io created
6serviceaccount/argocd-application-controller created
7serviceaccount/argocd-dex-server created
8serviceaccount/argocd-server created
9role.rbac.authorization.k8s.io/argocd-application-controller created
10role.rbac.authorization.k8s.io/argocd-dex-server created
11role.rbac.authorization.k8s.io/argocd-server created
12clusterrole.rbac.authorization.k8s.io/argocd-application-controller created
13clusterrole.rbac.authorization.k8s.io/argocd-server created
14rolebinding.rbac.authorization.k8s.io/argocd-application-controller created
15rolebinding.rbac.authorization.k8s.io/argocd-dex-server created
16rolebinding.rbac.authorization.k8s.io/argocd-server created
17clusterrolebinding.rbac.authorization.k8s.io/argocd-application-controller created
18clusterrolebinding.rbac.authorization.k8s.io/argocd-server created
19configmap/argocd-cm created
20configmap/argocd-rbac-cm created
21configmap/argocd-ssh-known-hosts-cm created
22configmap/argocd-tls-certs-cm created
23secret/argocd-secret created
24service/argocd-dex-server created
25service/argocd-metrics created
26service/argocd-redis created
27service/argocd-repo-server created
28service/argocd-server-metrics created
29service/argocd-server created
30deployment.apps/argocd-application-controller created
31deployment.apps/argocd-dex-server created
32deployment.apps/argocd-redis created
33deployment.apps/argocd-repo-server created
34deployment.apps/argocd-server created
1root@lab-kubernetes-1:~# kubectl get pod -n argocd
2NAME READY STATUS RESTARTS AGE
3argocd-application-controller-7684cfcc66-q8krm 1/1 Running 0 59s
4argocd-dex-server-675c85b57b-8v782 1/1 Running 0 59s
5argocd-redis-6d7f9df848-mn5hw 1/1 Running 0 59s
6argocd-repo-server-66784b696b-vkldr 1/1 Running 0 58s
7argocd-server-86cf69886-cvf56 1/1 Running 0 58s
On expose le déploiement afin d'avoir accès à l'interface web :
1root@lab-kubernetes-1:~# kubectl expose deployment argocd-server --type=NodePort --name=argocd-nodeport -n argocd
2service/argocd-nodeport exposed
3root@lab-kubernetes-1:~# kubectl get svc -n argocd
4NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
5...
6argocd-nodeport NodePort 10.110.131.45 <none> 8080:31278/TCP,8083:32691/TCP 6s
7...
Ici, nous pourrons y avoir accès au travers du port 31278.
Normalement vous devriez obtenir cette interface, via le protocole HTTPS :

Pour récupérer le mot de passe, voici la commande à saisir :
1root@lab-kubernetes-1:~# kubectl get pods -n argocd -l app.kubernetes.io/name=argocd-server -o name | cut -d'/' -f 2
2argocd-server-86cf69886-cvf56
Les identifiants ici sont : admin / argocd-server-86cf69886-cvf56

Ouf ! Enfin nous y sommes, nous allons pouvoir déployer notre site web avec notre Chart Helm créé précédemment !
Déploiement de notre Chart avec Argo CD
Maintenant que tout est en place, nous allons pouvoir créer une nouvelle application au sein d'Argo CD. Notre projet est publique et sur GitLab. Si jamais votre projet est privé, sachez que vous avez la possibilité d'ajouter vos repositories avec vos credentials sous Settings - Repositories.

Si votre registry Docker est privée, pensez à ajouter le nom de votre secret dans votre Chart sous imagePullSecrets.
Pour notre lab, nous n'aurons pas besoin de l'ensemble de ces credentials, nous allons directement passer à la création de l'application.
Rendez vous sur la page d'accueil, New App.
Sous Général, nous allons renseigner le nom de l'application argocd, le type de Project à default, ainsi que la Sync Policy à Automatic avec PRUNE RESOURCES de selectionné. De ce fait, Argo CD va synchroniser et détecter automatiquement les changements entre sa révision en local et le repository distant. De plus, il supprimera les ressources en local qui ne seront plus présents dans votre repository.

Sous Source, nous allons saisir notre projet GitLab. Pour moi ce sera https://gitlab.com/adrienpavone/argocd-static-website.git. Il faudra renseigner la révision que devra suivre Argo CD, sous HEAD. Enfin, le chemin sous lequel se trouve notre Chart, ici helm-argocd-website.

Concernant la partie Destination, je vais laisser le Cluster par défaut, et renseigner mon namespace personal. Ce sera le namespace au sein duquel Argo CD va déployer le Chart.

Pour terminer, Argo CD détecte automatique que sous le dossier renseigné précédemment se trouve un Chart Helm. Il va automatiquement créer les inputs et renseigner les valeurs par défaut que vous avez saisies au sein de votre fichier values.yaml.
Ici je vais juste modifier le champ image.tag pour enlever latest et mettre v0.0.1. Ensuite nous pouvons appuyer sur le bouton Create.


Pour tester, j'ai décidé d'apporter quelques modifications et d'ajouter d'autres tags à mon projet, jusqu'à la version v0.0.6. Mon application s'est automatiquement synchronisée et a d'ailleurs ajouter des révisions à chaque fois que j'ai modifié le champs image.tag.

Si je vais sur https://argocd.apav.one/, j'ai bien accès à ma ressource.
Cependant, comme nous pouvons le constater, nous rencontrons un problème de synchronisation avec le HPA. Si nous regardons plus en détails sur notre nœud Kubernetes, nous constatons qu'il n'arrive pas à collecter les métriques my_nginx_http_requests_total.
1root@lab-kubernetes-1:~# kubectl get hpa -n personal
2NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
3argocd-apav-one Deployment/argocd-apav-one 3%/50%, <unknown>/50 + 1 more... 3 10 3 101s
1root@lab-kubernetes-1:~# kubectl describe hpa argocd-apav-one -n personal
2Name: argocd-apav-one
3Namespace: personal
4Labels: app.kubernetes.io/instance=argocd
5 app.kubernetes.io/managed-by=Helm
6 app.kubernetes.io/name=argocd-apav-one-app
7 app.kubernetes.io/version=1.0.12
8 helm.sh/chart=helm-argocd-website-0.1.0
9Annotations: CreationTimestamp: Fri, 17 Jul 2020 18:29:26 +0200
10Reference: Deployment/argocd-apav-one
11Metrics: ( current / target )
12 resource memory on pods (as a percentage of request): 3% (9885696) / 50%
13 "my_nginx_http_requests_total" on pods: <unknown> / 50
14 resource cpu on pods (as a percentage of request): 1% (2m) / 50%
15Min replicas: 3
16Max replicas: 10
17Deployment pods: 3 current / 3 desired
18Conditions:
19 Type Status Reason Message
20 ---- ------ ------ -------
21 AbleToScale True ReadyForNewScale recommended size matches current size
22 ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from memory resource utilization (percentage of request)
23 ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
24Events:
25 Type Reason Age From Message
26 ---- ------ ---- ---- -------
27 Warning FailedGetPodsMetric 14s (x2 over 30s) horizontal-pod-autoscaler unable to get metric my_nginx_http_requests_total: unable to fetch metrics from custom metrics API: no custom metrics API (custom.metrics.k8s.io) registered
A vrai dire, c’est tout à fait normal puisque nous ne lui avons pas dit à quoi correspondait cette métrique, et comment la récupérer. Pour cela, nous allons avoir besoin d'un composant supplémentaire, Prometheus Adapter !
Déploiement de Prometheus Adapter
Prometheus Adapter va nous permettre d'écrire nos propres queries à destination du serveur Prometheus et donc de collecter les métriques dont nous avons besoin pour HPA.
Nous pourrions supprimer Metrics Server, et laisser en place seulement Prometheus Adapter en écrivant nos requêtes pour collecter la CPU et la Mémoire de nos containers. Pour ce lab, je vous montre qu'il est possible d'avoir les deux en place.
D'ailleurs Prometheus Adapter vous donne la possibilité de se synchroniser avec votre serveur Prometheus afin de récupérer l'ensemble des queries de base qui peuvent être lancées, pour cela il faudra laisser à true le paramètre rules.default, ce que nous allons faire ici.
Pour ce faire, vous allez avoir besoin d'une nouvelle fois d'Helm pour installer Prometheus Adapter (lien ici). Comme depuis le début de l'article, je vais récupérer les valeurs du fichier values.yaml afin de les adapter à mon besoin.
1root@lab-kubernetes-1:/opt/prometheus-grafana# helm inspect values stable/prometheus-adapter > prometheus-adapter.yaml
Pour notre besoin, nous allons spécifier à Prometheus Adapter l'url du serveur Prometheus :
1# Url to access prometheus
2prometheus:
3 url: http://prometheus-operator-prometheus
4 port: 9090
5 path: ""
Nous allons de même écrire notre query my_nginx_http_requests_total afin d'avoir les informations coté HPA. Ajoutez la requête au sein de rules, sous custom :
1rules:
2 default: true
3 custom:
4 - seriesQuery: '{__name__=~"nginx_http_requests_total",container!="POD",namespace!="",pod!=""}'
5 seriesFilters: []
6 resources:
7 overrides:
8 namespace:
9 resource: namespace
10 pod:
11 resource: pod
12 name:
13 matches:
14 as: "my_nginx_http_requests_total"
15 metricsQuery: irate(nginx_http_requests_total{<<.LabelMatchers>>,container!="POD"}[5m])
Il ne reste plus qu'à déployer :
1root@lab-kubernetes-1:/opt/prometheus-grafana# helm upgrade --install -f prometheus-adapter.yaml prometheus-adapter stable/prometheus-adapter -n metrics
2Release "prometheus-adapter" does not exist. Installing it now.
3NAME: prometheus-adapter
4LAST DEPLOYED: Fri Jul 17 18:45:16 2020
5NAMESPACE: metrics
6STATUS: deployed
7REVISION: 1
8TEST SUITE: None
9NOTES:
10prometheus-adapter has been deployed.
11In a few minutes you should be able to list metrics using the following command(s):
12
13 kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1
Vous pouvez vérifier l'ensemble de vos requêtes de type custom de cette façon (n'oubliez pas d'installer jq si vous voulez un joli rendu) :
1root@lab-kubernetes-1:~# kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 | jq .
2{
3 "kind": "APIResourceList",
4 "apiVersion": "v1",
5 "groupVersion": "custom.metrics.k8s.io/v1beta1",
6 "resources": [
7 {
8 "name": "jobs.batch/prometheus_tsdb_wal_truncate_duration_seconds_sum",
9 "singularName": "",
10 "namespaced": true,
11 "kind": "MetricValueList",
12 "verbs": [
13 "get"
14 ]
15 },
16...
17 {
18 "name": "jobs.batch/process_max_fds",
19 "singularName": "",
20 "namespaced": true,
21 "kind": "MetricValueList",
22 "verbs": [
23 "get"
24 ]
25 }
26 ]
27}
Si nous faisons un describe sur notre HPA pour vérifier que notre requête remonte correctement, voici le résultat :
1....
2Metrics: ( current / target )
3 resource memory on pods (as a percentage of request): 4% (10815488) / 50%
4 "my_nginx_http_requests_total" on pods: 500m / 50
5 resource cpu on pods (as a percentage of request): 1% (2m) / 50%
6....
Vous devriez constater que Prometheus a mis à jour sa configuration en scrapant automatiquement le Service Monitor déployé grâce au Chart Helm :

De plus, si vous ajoutez ce dashboard à Grafana, vous pouvez monitorer vos containers Nginx, voir le nombre de requêtes etc.
Test de performance - test du HPA
Afin de tester l'HPA, nous allons appliquer une forte charge sur le site. Nous appliquons une volumétrie de 200 requêtes par seconde.
Nous pouvons constater que l'HPA s'est enclenché et a déployé 2 pods supplémentaires pour encaisser la charge.

Conclusion
Voilà, c'est « tout » pour aujourd'hui. J'apprécie grandement Argo CD, mais n'en suis qu'au début de l'utilisation, j'aimerais élargir l'implication d'Argo dans mon environnement Kubernetes, avec des applications Statefuls, des bases de données, voir son comportement. Aujourd'hui j’apprécie pouvoir modifier mon code source et le voir se mettre à jour automatiquement dans mon environnement, avec une stratégie RollingUpdate.
Ce que je regrette à première vue aujourd'hui, c'est d'être OutOfSync sur le HPA, ce qui est dommage parce que ce n'est pas le cas et j'ai l'impression qu'il n'arrive pas à se synchroniser au niveau d'Argo, malgré le fait qu'il soit réellement UpToDate dans Kubernetes.

Ce qui serait intéressant ici serait par exemple d'avoir une ImagePullPollicy à Always, et mettre le paramètre image.tag en latest, pour des environnements de Dev ou de Qualif. Comme ça nous aurions un vrai Continuous Deployment. (je préfère malgré tout avoir des versions fixes 🙂 )
Si vous le souhaitez, vous pouvez retrouver l’ensemble des sources utilisées pour cet article ici : https://gitlab.com/adrienpavone/argocd-static-website.
Si vous avez des questions ou des améliorations à apporter concernant mon déploiement, des best practices, ou simplement réduire la taille de mes articles je suis preneur.
Merci pour votre lecture et à bientôt !
APavone